IBM Storwize Data Recovery Case Study: Storwize V3700 Business Server
Table Of Contents
show
This crashed server came to Gillware all the way from Spain. The client had an IBM Storwize V3700 server machine with eighteen enterprise-grade hard drives that had failed. They could try to mount the iSCSI targets on the server and, for a brief instant, see the data on their critical virtual machines. But they had no time to pull any data off of the server, for soon afterward, the volume containing their ESXi datastores would vanish.
The client got in touch with our data recovery client advisers online and after a consultation with our CEO and RAID recovery expert Brian Gill, took a flight to the United States and arrived at Dane County Regional Airport to deliver the server to our data recovery lab personally. No international boundaries or oceans were going to stop them from choosing the best data recovery company to recover their data.
IBM Storwize Data Recovery Case Study: Storwize V3700 Business Server
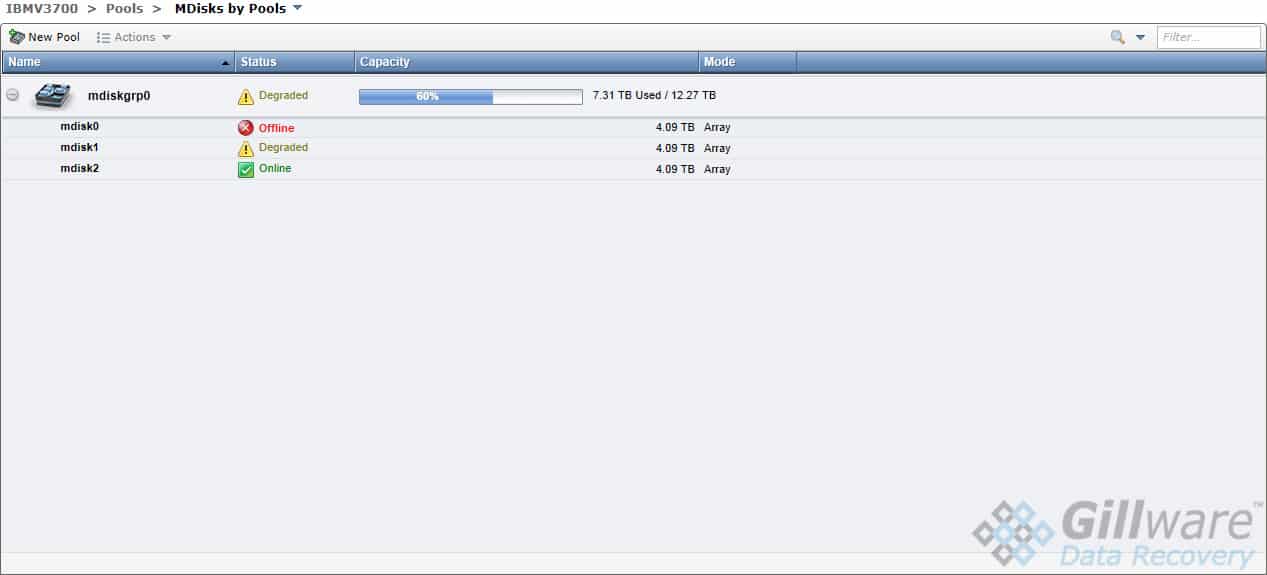
SAN Model: IBM Storwize V3700 Enterprise-Grade Server
RAID Level: 3x 6-drive RAID-5 arrays combined into 2 iSCSI targets
Drive Model: IBM Ultrastar HUC109090CSS600 900GB SAS
Total Capacity: 18 TB
Operating System: VMFS (ESXi virtual machine storage)
Situation: Two RAID-5 arrays were running degraded; one failed due to SAS errors and crashed the server
Type of Data Recovered: ESXi virtual machine datastores
Binary Read: 99.9%
Gillware Data Recovery Case Rating: 9
The IBM Storwize V3700 Server Setup
The eighteen enterprise-grade IBM hard drives made up three RAID-5 arrays in the client’s IBM Storwize server. In a RAID-5 array, one hard drive can fail without any loss of data, but if a second drive fails, the RAID crashes. The RAID controller can force a drive offline when it starts showing signs of failure. Some RAID controllers are extremely touchy and will force a drive offline if it so much as sneezes.
The three RAID-5 arrays worked together somewhat like a nested RAID-50 array, but not quite. A nested RAID-50 array takes several RAID-5 arrays and stripes them together as if the RAID-5 arrays themselves were individual drives in a RAID-0. This makes it so that no data will be lost as long as only one drive from each RAID-5 array fails.
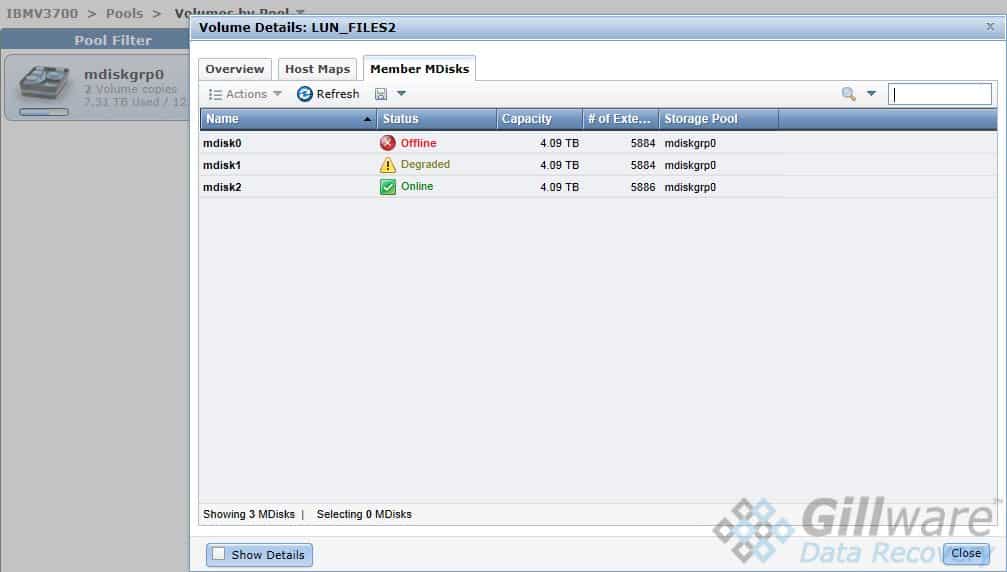
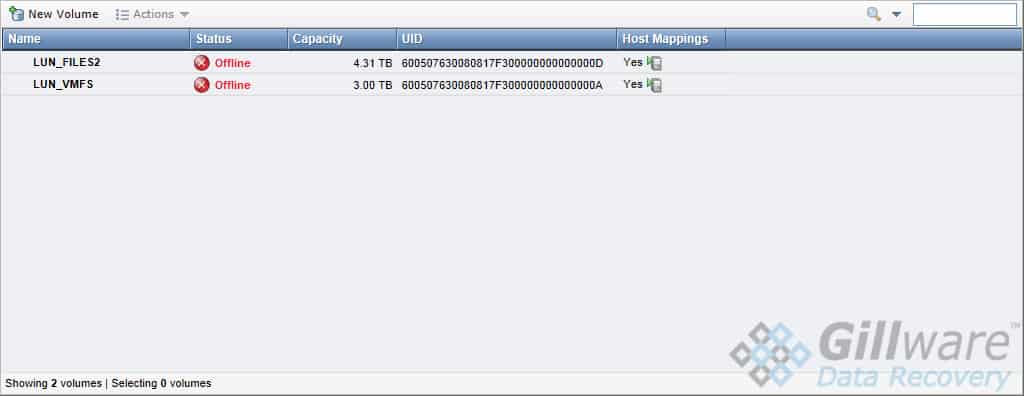
This IBM Storwize V3700 server’s RAID-5 arrays, however, were linked together in a very different way. Instead of using RAID-0 striping to create one logical volume, the V3700 created two iSCSI targets (also known as logical unit numbers, or LUNs) on the three RAID-5 arrays. The two targets each appeared to the users as single logical volumes. One target held a general company shared folder, while the other held a VMFS partition for VMWare ESXi datastores.
While this IBM Storwize business server was certainly not a RAID-50, the end result of this organization was that the server would fail if even one RAID-5 array lost two drives, forcing both iSCSI targets offline and rendering their data inaccessible.
Anatomy of a Server Crash
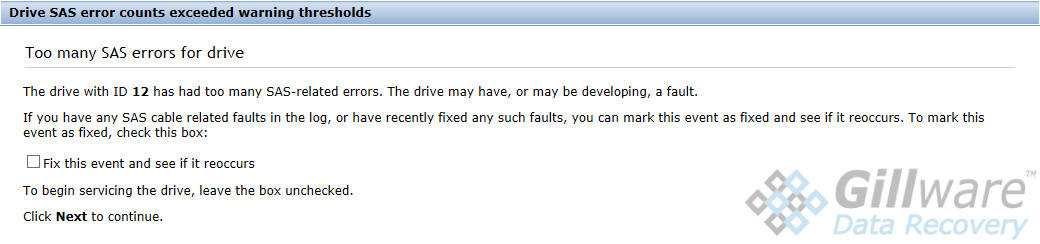
When a single drive in a RAID-5 fails, the array has to regenerate the content of the drive using the parity data on the rest of the drives. In this situation, a RAID-5’s health is said to be “degraded”.
Two of the RAID-5 arrays in this server had been running degraded for some time. In January, two drives in two separate RAID arrays had failed, and since then, both arrays had been running in a degraded state. The first drive(s) in a RAID array to fail are known as stale drives. As time passes and the degraded server continues its operations, the data trapped on the failed drives becomes increasingly out-of-date. Forcing stale data back into a RAID array causes massive data corruption.
If one drive from the third array failed, the server could have continued to limp along. But if a second drive from either degraded array failed, it would render both of the iSCSI LUNs the client’s business depended on inaccessible. Unfortunately for the client, the third drive to fail belonged to one of the two degraded RAID arrays.
IBM Storwize Data Recovery – Gameplan
Our engineers had two choices when it came to recovering the data from this crashed IBM Storwize SAN. We could image each disk, even the healthy ones, and write custom RAID controller emulation software to connect the disks properly. Or we could take advantage of the server chassis the client had graciously included and reconstruct the server in its own home.
The former is the technique we typically use to rebuilt RAID arrays in RAID data recovery cases, mainly because it is hardware-agnostic (all our RAID data recovery technicians need to do is convince the drives that they are hooked up properly, which they can do by creating custom software to emulate the RAID controller). But the latter would actually prove more fruitful in this case.
This Storwize server may have behaved just like a RAID-50 in practice. But the way the three RAID-5 servers were connected into two logical volumes was far more complex and far less predictable than the simple RAID-0 striping used in RAID-50 arrays. By addressing only the last failed drive and re-integrating its data into the Storwize server box itself and then pulling the data off of the degraded server, we could retrieve the client’s data for them sooner and with less hassle for our RAID recovery engineers.
However, our engineers found out about one data recovery roadblock early on in the recovery process. Imaging the last drive to have failed and cloning our forensic disk image to another enterprise-grade SAS hard drive wouldn’t cut the mustard: the IBM Storwize V3700 was extremely picky.
Getting the Server to Eat Its Veggies
Similar to many Dell EqualLogic servers, the IBM Storwize V3700 cares a lot about what kind of hard drive you put in it. Many of these enterprise-grade servers and SANs require the drives used to be of a specific brand and model. In this case, for example, the server exclusively used a specific model of 900 GB IBM Ultrastar with serial attached SCSI (SAS) connection protocols.
As our engineers soon learned, though, the Storwize V3700 didn’t just want a specific model of IBM Ultrastar. No, that wasn’t good enough. As it turned out, this IBM server kept track of which order the drives were meant to go in using their serial number, which meant that even if we used a IBM Ultrastar HUC109090CSS600 900GB SAS drive to clone the failed drive, the server would know immediately that the drive did not belong in the array and would completely refuse to accept it. Every serial number is different, after all (and if they weren’t, there wouldn’t be much of a point in having them).
And you thought getting your kid to eat their broccoli was like getting a tooth pulled…
There was only one course of action our server data recovery engineers could take if we wanted to stick to this recovery method. The most recently failed drive in the array had to be repaired, brought into functional shape, and brought back into the fold. The IBM Storwize server would accept nothing less than the genuine article.
IBM Storwize Data Recovery – Endgame
The most recently failed drive, which had been responsible for all of this mess, hadn’t had a major failure. For our data recovery experts, who see catastrophic hard drive failures every day, it was more like a very severe hiccup. Our fault-tolerant forensic imaging tools had helped us make a 99.9% forensic disk image (which hadn’t been enough to satisfy the server’s demanding standards).
Trying to repair the drive was a gamble. Getting it healthy enough to pull the data off of it had been child’s play for our cleanroom technicians. But if we couldn’t get the drive healthy enough for the IBM Storwize server to accept it, then our plan of attack would have utterly failed. We would have to go with plan B, which would involve a lengthy and difficult process of reasoning out exactly how the server had connected the three RAID-5 sub-arrays into two iSCSI target volumes.
After some minor repairs, our cleanroom engineers could get the failed IBM Ultrastar drive in good enough shape that the server would accept it. We knew at this point that we had a limited window of opportunity to copy off the client’s data. Hard drives generally don’t perform optimally when they have another drive’s parts inside them (at least not for long), and there was the omnipresent danger that this drive would quit on us and require even more extensive repairs.
Conclusion
Ultimately, this data recovery case turned out to be a rousing success. Our server recovery technicians successfully migrated the vast majority of the client’s data from the briefly-resuscitated server to a healthy transfer drive in the small time window we had to work on the server.
The client’s most critical data lived in their ESXi virtual machines. Our experts examined the virtual machines for signs of data corruption and found none. We shipped the recovered data back to the client in Spain via express international shipping. We rated this IBM Storwize recovery case a 9 out of 10 on our data recovery case rating scale.
